
-
Written by
-
on
-
. Posted in
Formal design verification is, for most medical device manufacturers, the most critical and resources intensive phase of the entire development life cycle.
The success of the medical device launch hinges on a correct (as in "Passed"), complete, consistent and most of all, compliant, verification results.
What are Dry Runs?
In theory
A Dry Run is an informal rehearsal of the verification testing execute the formal test cases in a non-formal setting.
The Dry Run evaluates, on one hand how well the test protocol performs and on the other hand whether medical device requirements have been implemented correctly in the device itself.
The idea is simple: your dry run a test case, identify all associated problems, address all these problems and can then be assured that the formal execution of the test case will pass.
Generally performed with considerably lower documentation requirements than formal verification, Dry Runs serve as a mean to lower the risk of failing tests during formal verification which can be very costly.
So even though all test cases are tested twice, it seems that we, all things considered, manage to hedge the risk of failing during formal verification and save ourselves some work.
One dry run and one formal execution is less work than two formal executions.
With these assumptions, we can allocate the appropriate staff and resources to the verification phase.
The idea is simple: your dry run a test case, identify all associated problems, address all these problems and can then be assured that the formal execution of the test case will pass.
In practice
With extensive experience in the medical device verification field, I have learned the hard way that there are several problems with these assumptions.
The illusion of the single dry run
The idea that a dry run is a single, clean rehearsal before the formal test is rarely true in practice. Most dry runs are iterative debugging sessions.
The initial dry run often uncovers obvious mismatches between the protocol and the implementation, leading to adjustments in the test procedure, the requirement interpretation, or the device behaviour itself.
But once fixes are applied, another dry run is typically performed to verify the changes. This cycle often repeats multiple times until the test is considered ready for formal execution.
Rarely do I see these repeats being considered during verification resource planning.
Dry runs are not that much less expensive than formal tests
While dry runs may lack the complete documentation burden of formal testing, they are still executed by the same qualified verification personnel.
In practice, the setup, execution, and evaluation time of a dry run closely mirrors that of a formal test—only with fewer official outputs. Since labor cost is the primary driver of verification expenses, the savings from reducing documentation can be marginal.
Furthermore, dry runs can create a false sense of economy, where informal test time is misclassified or underreported, resulting in less-than-optimal use of resources.
Dry runs are not the best way to catch errors
Tests written for formal verification, and inherently the Dry Runs as well, have a strong tendency to be so-called “happy path” test cases.
These are tests that verifies the system behaves exactly as expected under ideal conditions. It follows the most straightforward, error-free scenario in which:
- The user inputs only valid data.
- All preconditions are met.
- The system is in a normal, expected state.
- No unexpected events or edge cases occur.
It’s the “everything goes right” scenario.
This approach does little to surface edge cases, robustness issues, or subtle requirement ambiguities. Furthermore, without the accountability and rigor of formal testing, deviations from the procedure are more likely to go unnoticed or undocumented.
Relying on them as the main risk mitigation strategy can result in formal verification still catching defects, only later, at a higher cost and with more pressure.
The Expert's Secret
What is my expert advise to you in this situation?
Automate your Dry Runs
The "happy path," unambiguous test cases typically used during dry runs and formal verification may not be ideal for uncovering edge cases, usability flaws, or real-world failure modes.
However, they are perfectly suited for automation. These straightforward, deterministic test cases are stable, repeatable, and low in variability — exactly the characteristics needed for reliable automated execution.
By automating these tests, you significantly reduce manual effort, eliminate human error during execution, and create a scalable way to verify that the system continues to meet its core functional requirements.
Shift resources to exploratory testing
Once your dry runs are automated, an opportunity emerges: you can redirect your highly skilled verification personnel toward exploratory testing - one of the more underutilized but highly impactful testing strategies in medical device development.
Exploratory testing bridges the gap between formal compliance and real-world usability. Unlike scripted verification, which strictly follows predefined steps, exploratory testing allows testers to think like users, challenge the device in unexpected ways, and probe edge cases that formal test cases are not designed to capture.
This approach is uniquely effective at uncovering the nasty, real-world defects-the kind that frustrate end users and trigger costly post-market corrections.
Conclusion
This approach results in less resources needed, higher test coverage and more bugs found.
By automating routine dry run execution, you free up your human testers to do what they do best: think critically, adapt, and explore. This shift doesn't just improve test coverage-it directly improves product quality, safety, and customer satisfaction.
It's a strategic reallocation of resources that amplifies the impact of your verification effort without inflating your timeline or budget.
In short, automation gives you confidence. Exploratory testing gives you insight. Together, they make for a smarter, more resilient verification strategy.
About the Expert
Tobias Müller is a recognized voice in the world of test automation and software quality. With over 25 years in software development (including projects valued up to €160M), he brings hands-on experience in navigating complex, highly regulated environments.
He’s spoken at major industry events like AutomationGuild (where he was named a Top 10 Speaker) and led AI testing workshops during Malaysia’s National Training Week.
As the founder of TestResults, Tobias and his team are shaking up how companies approach automated testing: building smarter, faster, and more reliable solutions that go far beyond the usual script.
Accelerate your journey to CE Mark and FDA approval
Try aligned elements 30 days for free!

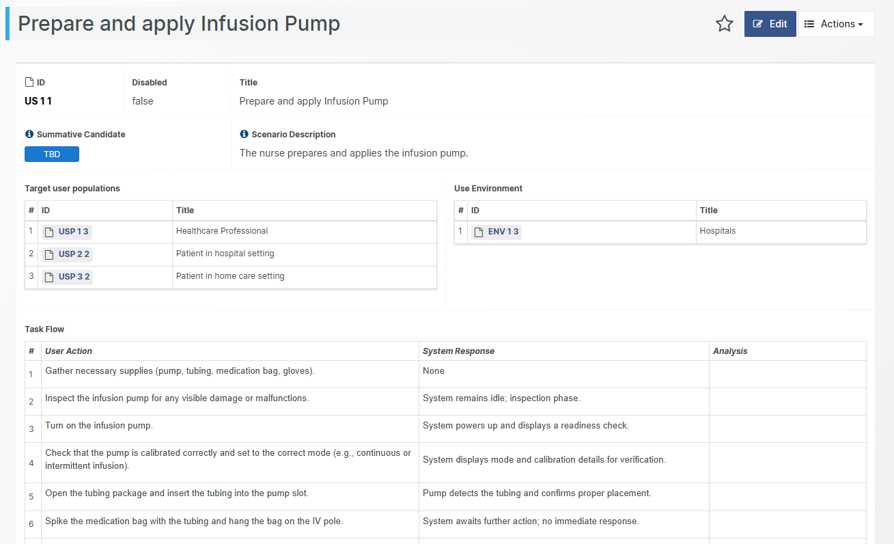
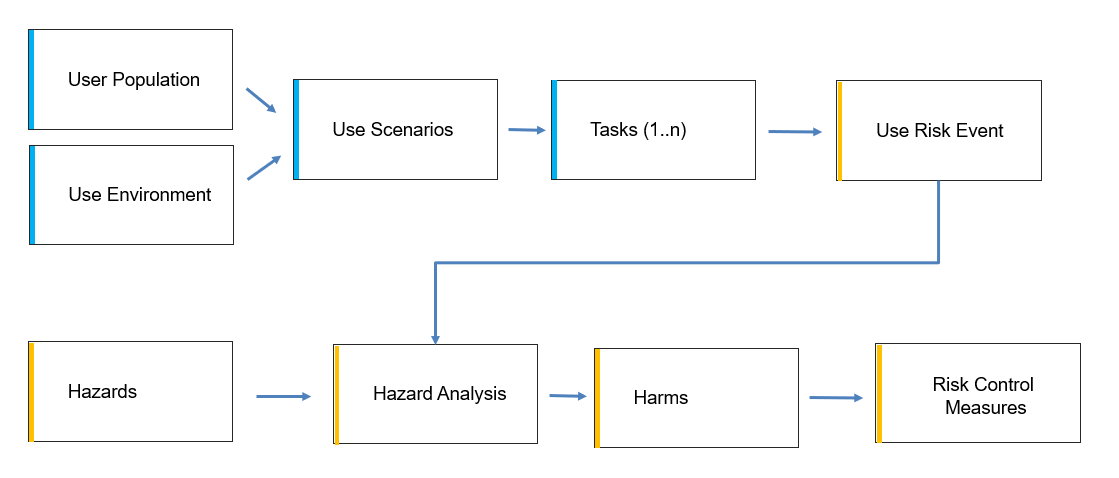












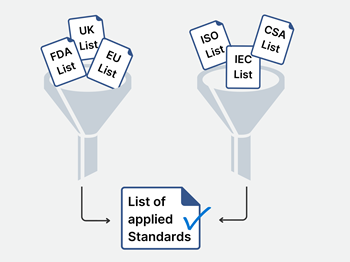






 Identify the applicable general requirements for separation of those parts, e.g. between enclosure parts and mains voltage parts in IEC 60601-1. The specification for such distances concerns creepage distances and air-clearances. Remember to consider dielectric strength test voltages for solid insulation materials.
Identify the applicable general requirements for separation of those parts, e.g. between enclosure parts and mains voltage parts in IEC 60601-1. The specification for such distances concerns creepage distances and air-clearances. Remember to consider dielectric strength test voltages for solid insulation materials.