I say "IEC 62304 Software Safety Classification", you say "A, B, C".
If you have worked with IEC 62304, you have (probably) also faced the challenge of assigning Software Safety Classifications to the Software Items. It has to do with associating a risk level to your software items in order to assess how careful you need to be when you document, develop and test them.
Now, if you work with medical device development, it has probably dawned on you that you are already doing risk management. Lots of risk management. All sorts of risk management. Is it possible to use the existing risk assessments when doing our IEC 62304 work? Yes, I think so.
When a software designer/architect constructs the software architecture needed for IEC 62304, there are lots of approaches to choose from. The norm is explicitly ambiguous on this point. In short, it is up to you to pick an approach. It is however not uncommon for the software designer to use established modeling techniques such as UML, Object-oriented design, multi-layered design, SAAS, etc. which in most cases results in a number of boxes (the software items) with names like:
- User Interface
- Logging
- User Management
- Reporting
- Data Access Layer
- Persistence
- Serial Communication etc.
So are we supposed to perform a risk assessment of these boxes now?
What strikes you immediately is the insight that these boxes in themselves do not "have" risk. Why? Because we have not defined the context in which they are used. Software risk emanates from how we use the software i.e. in which functional aspect we use the software items.
The guys of Certified Compliance Solution have solved this in a really neat way using what they call "The Matrix Model for Software Safety Classification". It is well summarized in the picture below.
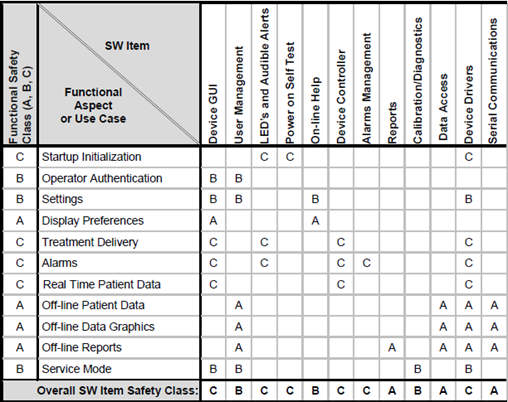
The CCE people have correctly identified that functional flows cut across the software architecture.
In their model, Software Items are listed on the horizontal axis, and User stories (or Epics, Use Cases, Work Flows, Specification, or whatever you want to call them) are listed on the vertical axis. Now, risk assessments for User Stories are something we do every day so that part should be pretty straight-forward. Once that is completed, we can deduct a classification for each User Story based on this risk assessment (more about that later).
The Software Designer can now point out the Software Items that implement our User Story in the software. After we have done this for all User Stories, the software Safety Classification for a Software Item is simply the highest risk of its aggregated use, which is summarized in the bottom line "Overall SW Item Safety Class".
Isn't it beautiful?
Let me show you how this is implemented in Aligned Elements.
First, I introduce the Document Object type "Use Case" which will represent the user stories. Then I set up Document Object types for Software System, Software Item, Software Unit, and SOUP which all have a Software Safety Class attribute being A, B, or C, with the default value C.
I can then proceed to document the Use Cases and structure the Software Architecture separately.
Now, time for risk assessment. I will use the integrated Preliminary Hazard Analysis (PHA) to assess my Use Cases. When working out the risks using the PHA method, I am requested to define the possible Cause(s) for each risk. The Cause has a severity attribute and I will use this severity to calculate the Software Safety classification. If the Cause is emanating from the software, I further tag the Cause originator as "Software".

I go back to the Software Item definition and map the values A, B, and C to a Severity range in the Cause i.e. a Severity from 1-3 maps to Class A, Severity 3-5 maps to Class B, etc.
To tie it all together, I trace the Use Cases to the PHA risks and (here comes the trick) Software Items to the software originated Causes.

I run an Inconsistency analysis on the Software Items and get a report on how well the Software Item Safety classifications match the risk assessment, including suggestions on what the Software Safety Classification ought to be based on the associated risks.

Simple, transparent, and consistent.
So we have a range of benefits from this approach:
- We perform risk assessment where it makes sense i.e. to Use Cases.
- When we map use cases to software items via the risks, automatic checks will ensure that the maximum severity of the risks matches with the software item safety class.
- We have reused the use case risk assessment in our IEC 62304 implementation.
- We have used traces to establish the relationships between use case, risk and software items and automatically get the required traceability for free.
Once again we have shown the benefit of integrating all Design Control Items in a single system.
The sum is truly greater than its parts.
{fastsocialshare}